港大經管學院今日發表《大語言模型幻覺控制能力測評報告》,針對選定的AI大語言模型(LLM)評估其幻覺控制能力。「幻覺」是指AI會輸出看似合理卻與事實相悖或偏離語境的內容。現時,大語言模型(LLM)正積極於知識服務、智能導航、客戶服務等專業應用場景中推進。 然而,「幻覺」現象仍是制約其可信度的關鍵瓶頸。
該研究由港大經管學院創新及資訊管理學教授兼夏利萊伉儷基金教授 (戰略信息管理學)蔣鎮輝教授率領人工智能評測實驗室(AIEL)(https://hkubs.hku.hk/aimodelrankings)研究人員發起,針對 37個中美大語言模型(包括20個通用模型、15個推理模型及2個一體化系統)在中文語境下的幻覺控制能力開展專業評測,揭示不同模型在規避事實錯誤與保持語境一致性方面的真實表現。
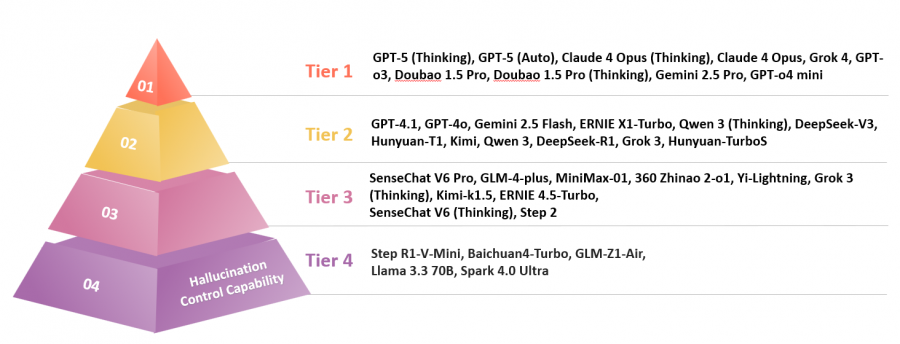
評測結果顯示,GPT-5(思考模式)和GPT-5(自動模式)分別位列第一第二,Claude 4 Opus系列緊隨其後;字節跳動公司的豆包1.5 Pro系列表現突出,在中國大語言模型陣營中處於領先地位,但與國際頂尖模型之間仍存在顯著差距。
蔣鎮輝教授表示:「幻覺控制能力作為衡量模型輸出真實性與可靠性的核心指標,直接影響大語言模型在專業場景中的可信度。 該研究為未來模型的優化提供了明確方向,推動AI從『能生成』向更關鍵的『可信賴』邁進。 」
評測方法
根據模型生成內容在事實依據或語境契合度上存在的問題,該研究將「幻覺」分為兩類:事實性幻覺和忠實性幻覺。
事實性幻覺是指模型輸出內容與真實世界資訊不符,既包括對已知知識的錯誤調用(如張冠李戴、數據錯記),也包括對未知資訊的虛構(如編造未驗證的事件、數據)。 研究透過訊息檢索類問題、虛假事實識別類問題,以及矛盾前提識別類問題,檢測不同模型針對事實性幻覺的控制能力。
忠實性幻覺是指模型未能嚴格遵循使用者指令,或輸出內容與輸入上下文矛盾,包括遺漏關鍵要求、過度引申、格式錯誤等。 研究透過指令一致性評估問題及上下文一致性評估問題,檢測不同模型針對忠實性幻覺的控制能力。
幻覺控制能力梯隊
根據評測結果,GPT-5(思考模式)和GPT-5(自動模式)分別位居第一名和第二名,Claude 4 Opus系列緊隨其後;字節跳動公司的豆包1.5 Pro系列在中國大語言模型陣營中表現突出,但與國際頂尖模型之間仍存在顯著差距。
|
排名
|
模型名稱
|
事實性幻覺
|
忠實性幻覺
|
最終得分
|
|
1
|
GPT 5(思考模式)
|
72
|
100
|
86
|
|
2
|
GPT 5(自動模式)
|
68
|
100
|
84
|
|
3
|
Claude 4 Opus(思考模式)
|
73
|
92
|
83
|
|
4
|
Claude 4 Opus
|
64
|
96
|
80
|
|
5
|
Grok 4
|
71
|
80
|
76
|
|
6
|
GPT-o3
|
49
|
100
|
75
|
|
7
|
豆包1.5 Pro
|
57
|
88
|
73
|
|
8
|
豆包1.5 Pro(思考模式)
|
60
|
84
|
72
|
|
9
|
Gemini 2.5 Pro
|
57
|
84
|
71
|
|
10
|
GPT-o4 mini
|
44
|
96
|
70
|
|
11
|
GPT-4.1
|
59
|
80
|
69
|
|
12
|
GPT-4o
|
53
|
80
|
67
|
|
12
|
Gemini 2.5 Flash
|
49
|
84
|
67
|
|
14
|
文心一言 X1-Turbo
|
47
|
84
|
65
|
|
14
|
通義千問3(思考模式)
|
55
|
76
|
65
|
|
14
|
DeepSeek-V3
|
49
|
80
|
65
|
|
14
|
混元-T1
|
49
|
80
|
65
|
|
18
|
Kimi
|
47
|
80
|
63
|
|
18
|
通義千問3
|
51
|
76
|
63
|
|
20
|
DeepSeek-R1
|
52
|
68
|
60
|
|
20
|
Grok 3
|
36
|
84
|
60
|
|
20
|
混元-TurboS
|
44
|
76
|
60
|
|
23
|
日日新 V6 Pro
|
41
|
76
|
59
|
|
24
|
GLM-4-plus
|
35
|
80
|
57
|
|
25
|
MiniMax-01
|
31
|
80
|
55
|
|
25
|
360智腦2-o1
|
49
|
60
|
55
|
|
27
|
Yi- Lightning
|
28
|
80
|
54
|
|
28
|
Grok 3(思考模式)
|
29
|
76
|
53
|
|
29
|
Kimi-k1.5
|
36
|
68
|
52
|
|
30
|
文心一言4.5-Turbo
|
31
|
72
|
51
|
|
30
|
日日新 V6推理
|
37
|
64
|
51
|
|
32
|
Step 2
|
32
|
68
|
50
|
|
33
|
Step R1-V-Mini
|
36
|
60
|
48
|
|
34
|
Baichuan4-Turbo
|
33
|
60
|
47
|
|
35
|
GLM-Z1-Air
|
32
|
60
|
46
|
|
36
|
Llama 3.3 70B
|
33
|
56
|
45
|
|
37
|
Spark 4.0 Ultra
|
19
|
64
|
41
|
圖表 1:幻覺控制能力綜合排名
是次研究涵蓋的37個模型的幻覺控制能力得分及排名整體呈現出顯著的梯度差異,且在事實性與忠實性幻覺控制上表現出不同的能力特徵。
綜合而言,目前大模型在忠實性幻覺控制上已相當強勁,但在事實性幻覺領域上仍有不足之處,反映出這些模型目前普遍存在「嚴守指令,但易虛構事實」的傾向。
此外,推理模型的幻覺控制能力相對表現較好,例如通義千問3(思考模式),文心一言 X1-Turbo和Claude 4 Opus(思考模式)等推理模型的幻覺控制能力比同系列通用版本更佳。
在中國大語言模型中,豆包1.5 Pro系列位於領先地位,在事實性幻覺控制和忠實性幻覺控制的領域得分均衡,展現出穩健的幻覺控制能力;然而,其綜合能力與GPT-5和Claude系列仍有差距。 相比之下,DeepSeek系列的幻覺控制能力稍顯遜色,有待加強。
請按此瀏覽《大語言模型幻覺控制能力深度測評報告》全文。
總括而言,本次評估透過事實性同忠實性的分類框架,深入闡述大語言模型幻覺控制能力的核心理論基礎與模型表現。未來, AI可信度需兼顧控制事實性幻覺與忠實性幻覺兩個領域的能力,以產出更可信賴的內容。
請按此下載高清圖片。
傳媒垂詢,請聯絡: